Liquid Cooled Workstation: Advantageous for Big Ocean Simulations, Exceptional for Small Tasks (Oregon State + Mark III + NVIDIA + Supermicro)
Special Guest Blog by Oregon State University
Why is a GPU workstation useful?
Many companies, hospitals and universities have started to downsize their server room resources on premises. This happens when groups need to upgrade or replace aging power and cooling systems in these server room spaces. This, coupled with reduced access to labor to run the infrastructure hardware, leads groups to look at other solutions to leverage high-end computing resources without the need for a server room. This becomes doubly important for groups trying to leverage AI based pipelines, because HPC systems that are built for integration of GPU technology require larger than normal cooling and power. Cloud services are one route to access GPU technology, but these services can be expensive when working with massive quantities of data like those used in scientific research. GPU workstations provide an alternative route to access GPU technology that can be set up in labs or office spaces. Many companies already have adequate cooling and power for workstation-class machines throughout their facilities and, in contrast to server-class machines, these workstations are portable and relatively quiet, allowing them to be set up in lab, field, or office spaces.
The liquid cooled Supermicro AI GPU workstation (SYS-751GE-TNRT) brings server-level technology straight into the lab or office, becoming directly accessible to the researcher or end users. This new workstation can be configured in many ways to accommodate the needs of a gamut of workloads and to align with the proper cost to compute models for any group. For our tests, we configured the machine to have a single NVIDIA T400 4GB card for local video output and 4x NVIDIA A100 Tensor Core GPUs for the processing of our simulations and pipelines. The machine was configured with NVIDIA NVLink to allow our workloads to scale multi-GPU communications and shared memory at 600GB/s, 19X faster than PCIe gen 3.
Putting the technology closer to the researcher allows for more rapid changes to the system to accommodate new pathways and upgrades. This becomes especially important with AI-based software stacks that evolve at an alarming rate, causing researchers to wait for HPC administration staff to implement software upgrades while working around already scheduled jobs from other users. In many HPC infrastructures, the GPU resources are also limited and overbooked for work waiting to be processed. This new workstation allows groups to bring GPU technology straight into the lab, enabling user-tailored software and pipelines without compromising processing power compared to the larger, more expensive servers.

GPU-accelerated Ocean Simulations
The ocean plays a critical role in the Earth system, mediating changes in climate and providing a habitat for much of the life on Earth, but the ocean also contains a rich array of difficult-to-observe processes spanning from basin-wide gyres that create ocean “garbage patches”, down to centimeter-scale eddies that transfer properties at the air-sea interface. Ocean models allow scientists to probe the many ocean processes that are challenging to observe. These models are also our window to the future, allowing us to project how the global ocean and wider climate system could change in the future, the latter by coupling to models for other Earth system components (e.g., atmosphere, sea ice). Unfortunately, most ocean models are based on decades-old code that is difficult to use and cannot leverage modern hardware developments. As a result, simulations of complex systems like those conducted by CMIP (Coupled Model Intercomparison Project) for the IPCC (Intergovernmental Panel on Climate Change) reports, require huge allocations (10,000s of CPUs) on HPC systems around the world.
Oceananigans is a Julia-based software package that simulates the ocean’s physics, chemistry, and biology. Despite being a new research tool, Oceananigans is gaining popularity among ocean and climate scientists for several reasons: it is open-source, user-friendly, and has flexibility in both the hardware it can utilize (GPUs or CPUs) and the breadth of ocean systems it can simulate (from the global ocean to fine-scale mixing at the ocean’s boundaries). Recent studies demonstrate that Oceananigans can leverage GPU clusters to perform simulations of the global ocean quickly and at unprecedentedly high resolution, a critical step towards creating an Earth System Model (ESM) for future computing architectures.
Ocean simulations typically split the ocean into several grid cells and step forward (evolve) the momentum, temperature, and other properties of each cell using information from previous times and other nearby cells. The number of grid points in a specific simulation depends on the size of the domain and the desired spatial resolution of the simulation, but it is common for both global ocean and small-scale simulations to have millions (and sometimes billions) of grid points. This makes GPUs, with the ability to perform many simultaneous calculations, an appealing candidate hardware for future ocean modeling experiments.
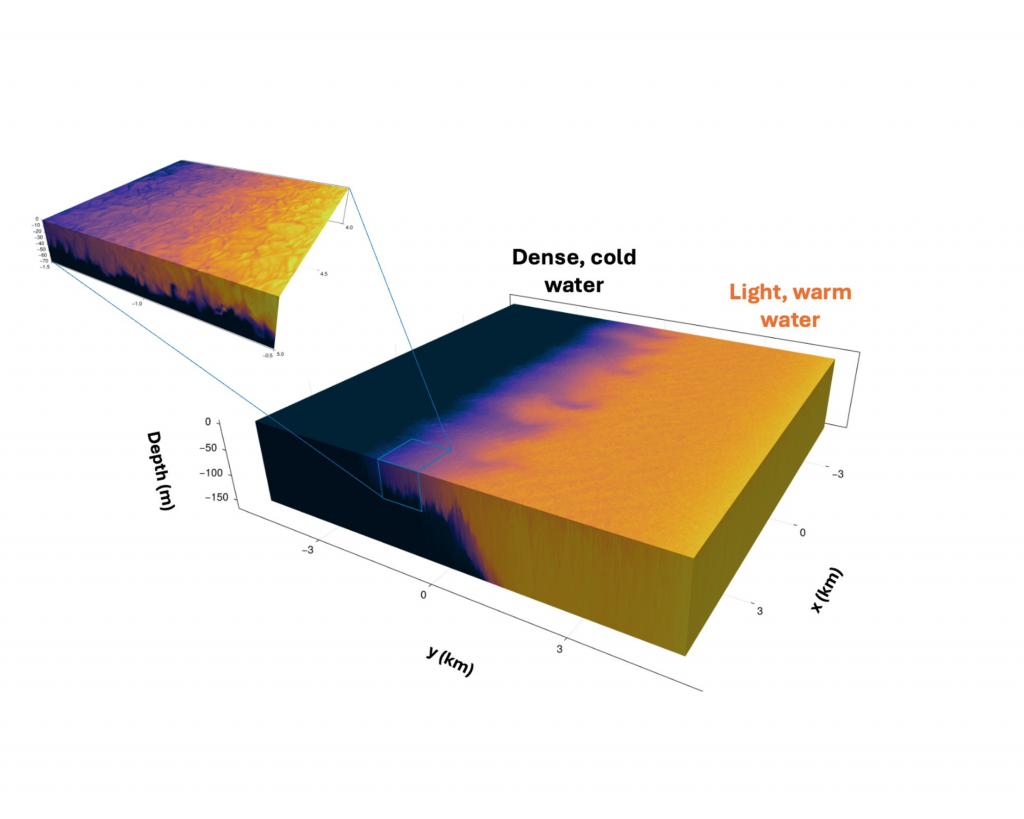
Figure 1 – Oceananigans simulation of an ocean front (colors denote temperature), which resolves the simultaneous evolution of large- and small-scale mixing. This simulation was run with an A100 on the liquid-cooled workstation.
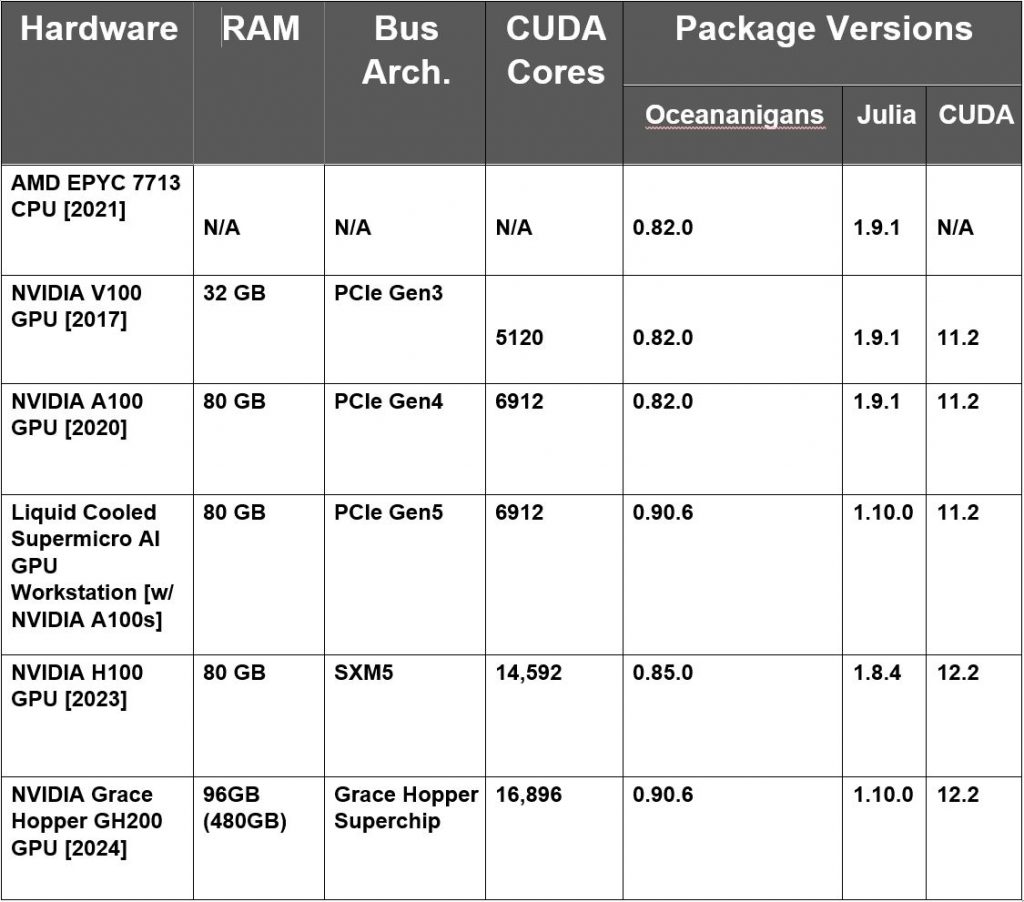
In this blog we show how different GPU hardware, including the liquid cooled Supermicro AI GPU workstation (SYS-751GE-TNRT), can be leveraged by Oceananigans to perform simulations of the turbulent upper-ocean, providing a window into the physics and biogeochemistry at the air-sea interface (See Figure 1). Our analysis focuses on the speed (wall time) and efficiency (energy consumption) of ocean simulations across different hardware, and how these metrics are affected by the number of simulated grid points (or equivalently the domain size since we do not vary spatial resolution). In addition to the Supermicro AI GPU Workstation, which contains four liquid cooled NVIDIA A100 GPUs, we utilized several generations of NVIDIA GPU in air-cooled HPC environments, including NVIDIA A100 and H100 Tensor Core GPUs and NVIDIA GH200 Grace Hopper Superchip (see Table).
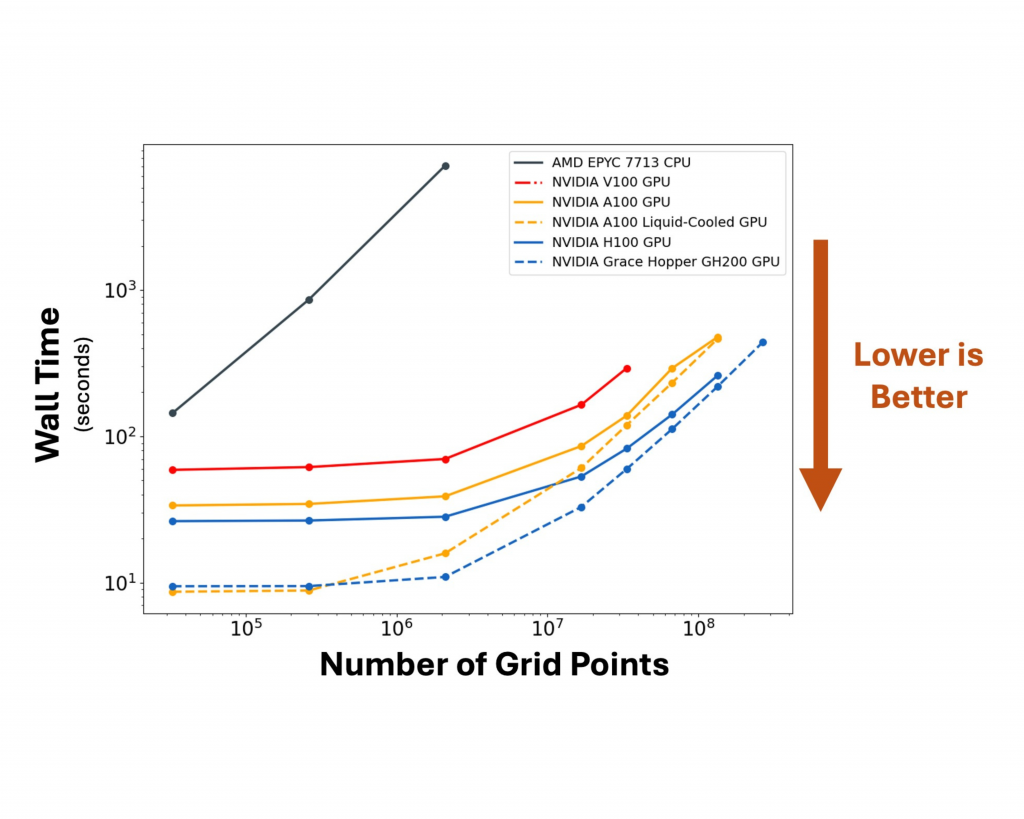
Figure 2 – Wall time as a function of simulation size for various GPU and CPU hardware.
Advantages of General GPU Hardware
For CPU hardware in Figure 2 (black line), as expected the wall time of ocean simulations increases linearly with the number of grid points being simulated because a single core conducts one operation (e.g., grid cell calculation) at a time. This results in CPU energy consumption that increases linearly with the wall time and hence the number of grid points being simulated (Figure 3).
In contrast, the GPUs show distinct behavior vs. CPUs in Figure 2. For the smallest GPU simulations, the wall time is not affected by the number of simulated grid points. The wall time only grows linearly for the largest simulations (>~10 million grid points). This suggests a transition from a small-simulation regime where the GPU is unsaturated (it does not fully utilize its hardware resources), so wall speed is limited by the base speed of data/memory process (read/write/transfer), to a large-simulation regime where the GPU is saturated so the wall speed is constrained by the total number of calculations and/or memory load, which both increase with the number of grid points. These regimes also manifest in the energy efficiency of GPU simulations (Figure 3), where the energy required for the smallest (unsaturated) simulations does not increase with the simulation size, only growing linearly in the large-simulation (saturated) regime where the increasing wall time of simulations produces a corresponding increase in energy consumption.
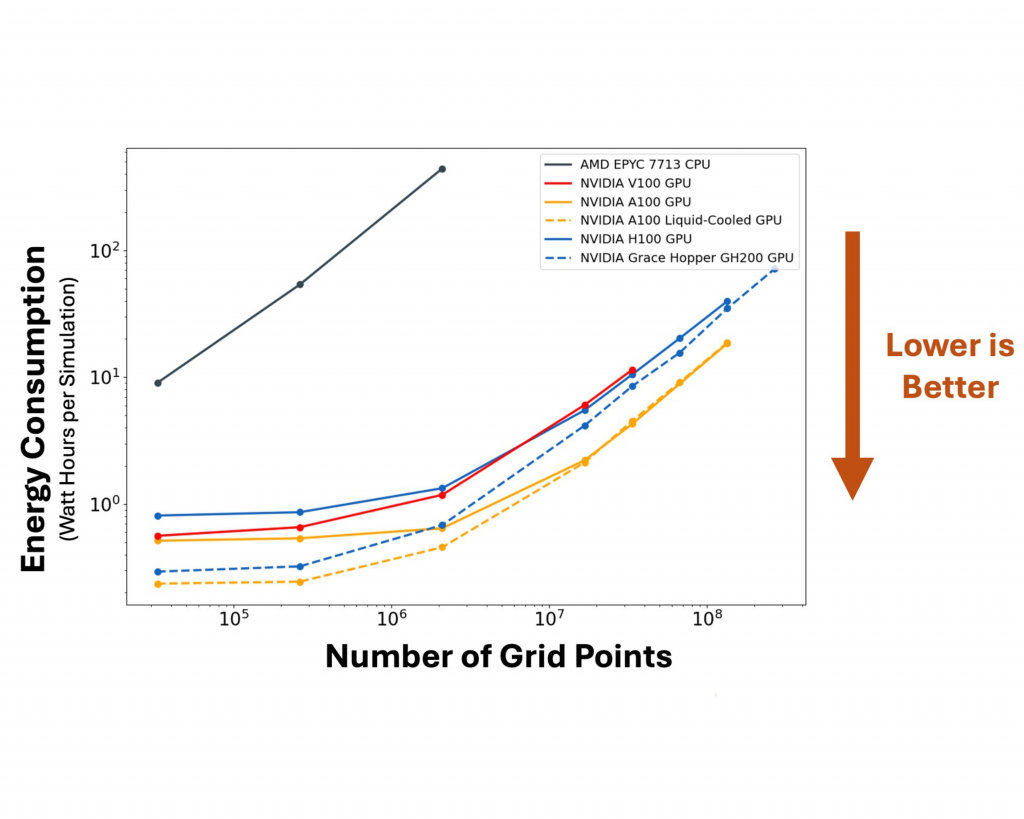
Figure 3- Energy consumption as a function of simulation size for various hardware.
Contrasting Different GPU Hardware
For small simulation workloads where GPUs are unsaturated, the liquid cooled workstation outperforms all the tested air-cooled GPU configurations, including the NVIDIA HGX H100 and NVIDIA GH200 Grace Hopper Superchip. For the smallest simulation (32 x 32 x 32) the liquid cooled workstation completes the simulation in 8.6 seconds, faster than the newer-generation air-cooled NVIDIA GH200 (9.6 seconds) and air-cooled NVIDIA H100 (26.3 seconds), as well as the air-cooled NVIDIA A100 (33.6 seconds). As a result, for the smallest simulations the NVIDIA A100 GPUs within the liquid cooled workstation are more energy efficient than both the air-cooled NVIDIA A100 (which takes much longer) and the newer-generation GPUs (which have a greater power draw).
For the largest simulations where GPUs are saturated, the fastest runs are achieved with the newest-generation NVIDIA GH200 and H100 air-cooled accelerators (Figure 2), but the liquid- and air-cooled NVIDIA A100s are the most energy-efficient hardware (Figure 3). The liquid cooled workstation is still 3% faster than the air-cooled A100 for the largest simulation, while the H100 and GH200 are roughly twice as fast, but consume twice as much energy, as the A100 systems. Figures 2 & 3 also show that the size of the largest conducted ocean simulation varied across hardware due to their differing memory capacity. The largest V100 (32GB RAM) simulations had 2563 grid points, the A100 systems and the H100 (all 80GB) simulated up to 5123 grid points, and the GH200 (96GB) simulated up to 512 x 512 x 1028 grid points. These maximum domain sizes would vary with other simulation specifics, such as the number of evolved variables/tracers.
After looking through the data, liquid cooling increases performance and reduces power consumption over the same hardware using standard air cooling. This will be true for future revisions of this hardware with newer NVIDIA GPU technologies and any server-class hardware that already leverages liquid cooling. This can become especially beneficial when doing small jobs like business transactions or inference for AI data. In general liquid cooling should lower the overall power consumption used for performance returned even when looking at HPC server rooms. This will help engineers overcome the power challenges in the future while helping scientist use new technologies to solve our world’s greatest problems.
Hardware Table:
Authors:
Alana Kihn - Oregon State University College of Engineering
Brodie Pearson - Oregon State University College of Earth, Oceans and Atmospheric Sciences
Gregory Wagner – MIT, Department of Earth, Atmospheric, and Planetary Sciences
Thomas Olson - Oregon State University College of Earth, Oceans and Atmospheric Sciences
Christopher M. Sullivan - Oregon State University College of Earth, Oceans and Atmospheric Sciences