Liquid Cooled Workstation for Large-Scale Edge Data Science (Oregon State + Mark III + NVIDIA + Supermicro)
Special Guest Blog by Oregon State University
Why is a GPU workstation useful?
The Pacific Northwest (PNW) Bioacoustics Lab is based in Corvallis, Oregon, and operates in a close partnership between the US Forest Service Pacific Northwest Research Station and Oregon State University. It has been using AI (artificial intelligence) for animal identification for many years and is now seeking at how to increase the sampling rate and reduce data ingestion through edge computing technologies.
Currently, the lab conducts passive acoustic monitoring using over 3,600 Autonomous Recoding Units (ARU) within the Pacific Northwest (PNW) Forest and collects over 150 Terabytes of data every season. Sound monitoring data is paired with camera-trap images to create a better overall classification of wildlife in the northwest forest and other forests around the world. These raw data (both image and sound) are processed using NVIDIA GPUs in the Oregon State University Center for Quantitative and Life Science High Performance Computing (HPC) cluster and turned into over 300 Terabytes of output after segmentation and inference using large servers. All this data collapses to an exceptionally large Comma Separated Values (CSV) file, providing the lab with a look at the different species through the PNW forest over time. Because the process of collecting the data is very labor-intensive and time consuming, the usability of this pipeline is limited, since this process can only be done several times each year. To increase visibility more regularly, the lab wants to leverage edge devices to collect and help aggregate the data to a central location at the edge, followed by processing the data at the centralized edge location and sending the smaller CSV output back to the lab through a cellular or satellite network.

To move in this direction, the PNW Bioacoustics Lab is working with Supermicro to test a new piece of technology that enables edge AI. This modern technology is a liquid cooled Supermicro AI GPU Workstation (SYS-751GE-TNRT) with the ability to do inference and training at the edge or just about anywhere you need. The Supermicro AI GPU Workstation uses liquid cooling for both the CPUs (central processing unit) and GPUs. Not only does it allow CPUs and GPUs to run at maximum performance, but the system has been developed to be run in office environments, with the ability to reduce noise by up to 90%.
The PNW Bioacoustics Lab plans to test this machine with two different configurations. The main configuration to do AI at the edge includes testing real-time or semi-real-time processing, where we see output once an hour, and large model training to help find hidden animals. After the inference is made, the lab would like to test retraining from newly found data to create a more accurate model. The second configuration looks at this machine as a workstation a researcher can directly use to manage an AI experiment from start to finish at their desk. This includes using the workstation to label images, train different models, and apply inference for large-scale data science experiments.

YOLOv5/8
To fully test the system quickly and using tools everyone can leverage, the Bioacoustics Lab decided to leverage You Only Look Once (YOLO) version 5 and 8. This allowed tests of different size models, as well as different batches and image sizes. YOLO is a well-known object detection algorithm that is open-source and accessible to everyone, so the tests should be relevant to the larger AI community. The lab works with sound data and image data and will use primarily image data for this testing. Testing the processing capabilities will be crucial to showing the system can successfully ingest substantial amounts of data and process it in real or semi-real time. We plan to show we can collect data and then segment CPUs while classifying GPU at the same time.
The PNW Bioacoustics Lab has managed images to work with and train from for use with different AI tools. The lab worked to build an elegant labeling tool called OSU Njobvu-AI (https://arxiv.org/pdf/2308.16435.pdf ). This tool is easy to install and works on desktops and servers through a web browser since it leverages Node.js. Because the new liquid cooled Supermicro AI GPU Workstation (SYS-751GE-TNRT) has an NVIDIA T400 (4G) card for normal video output, we were easily able to leverage this with the labeling tool. The Njobvu-AI tool has YOLO integrated into the web interface so users can train a model on the 80 GB NVIDIA A100 Tensor Core GPUs once they are done labeling new images. This set of tools were perfect to test the Liquid Cooled GPU workstation.
Workstation tests
The YOLOv5 algorithm has been considered state-of-the-art in computer vision models since its release in 2020. More recently, the updated YOLOv8 model was released in 2023 and promised improvements in performance over earlier versions. Both models are available in different sizes (e.g., nano, small, medium, large, extra-large), which have increasing numbers of parameters. YOLOv5 models were designed to accommodate training images of varying sizes up to 1280×1280; however, newer YOLOv8 models currently only accept images up to 640×640.
Using larger image sizes during training allows for models to learn and predict at higher resolution, which can improve detection and classification of small objects. However, using larger image sizes is more computationally expensive. Similarly, using larger batch sizes allows for more images to be seen simultaneously during training and is understood to produce more accurate models, but increasing batch size also increases GPU usage. Therefore, limitations in computing power often restrict the ability of researchers to train the best-performing models.
We conducted training runs using YOLOv5 and YOLOv8 models of varied sizes with different batch size and image size parameters. We used small (14–22 MB) and medium (41–50 MB) models as recommended for edge computing. These runs all used a dataset of 71,580 training images (including approximately 10% background images) and ran for 100 epochs. We monitored runtime and maximum memory usage for each training run (below). We validated each model on a separate dataset of 15,260 images (approximately 10% background) and evaluated performance using the mean average precision values at an intersection-over-union (IOU) threshold of 0.5 (mAP50) as reported by the ultralytics package.
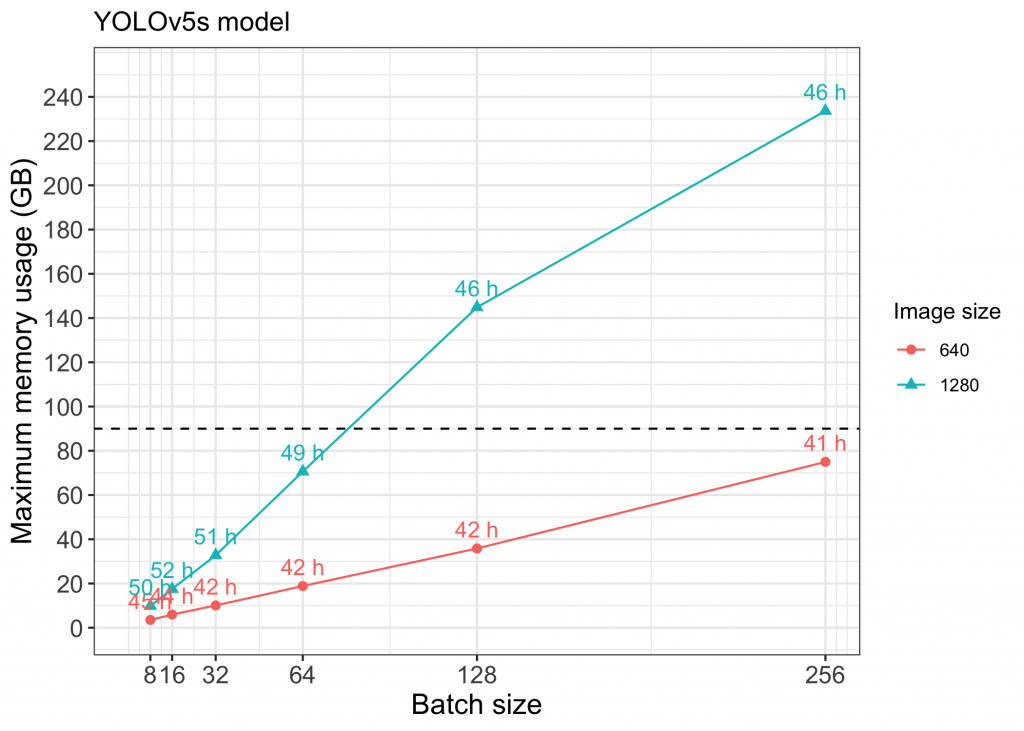
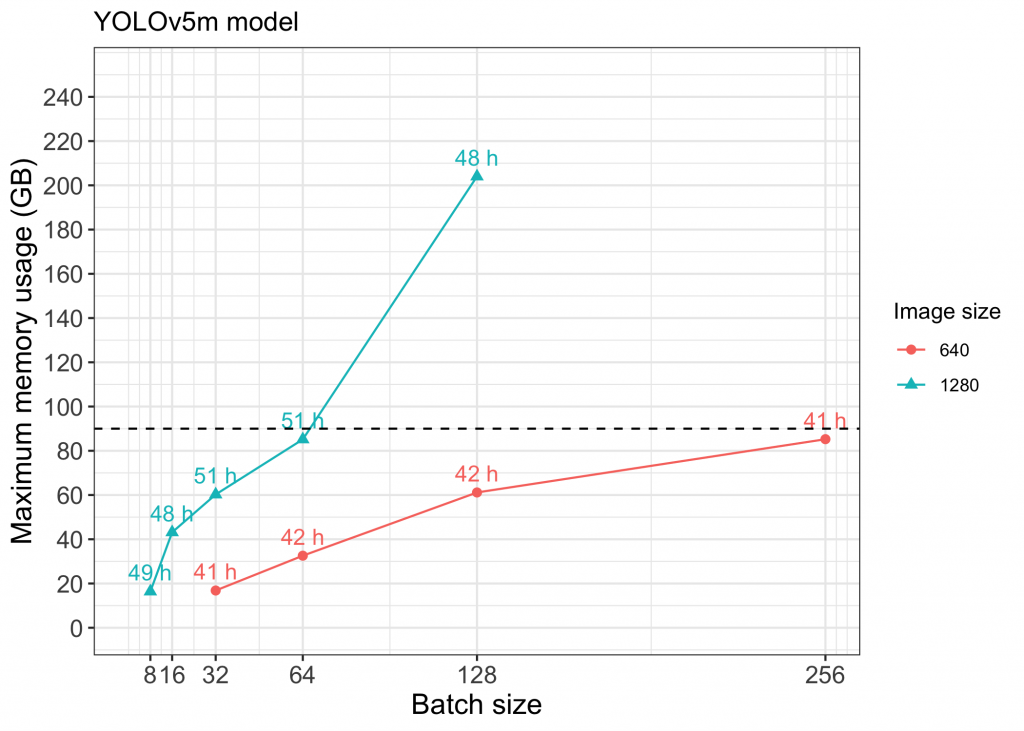
Figure 1 Memory vs Batch size for small models using YOLOv5. Points above the dashed line (approx. GB limit for each GPU) indicate runs that used NVIDIA NVLink to utilize multiple GPUs.
Figure 2 Memory vs Batch size for medium models using YOLOv5. Points above the dashed line (approx. GB limit for each GPU) indicate runs that used NVIDIA NVLink to utilize multiple GPUs.
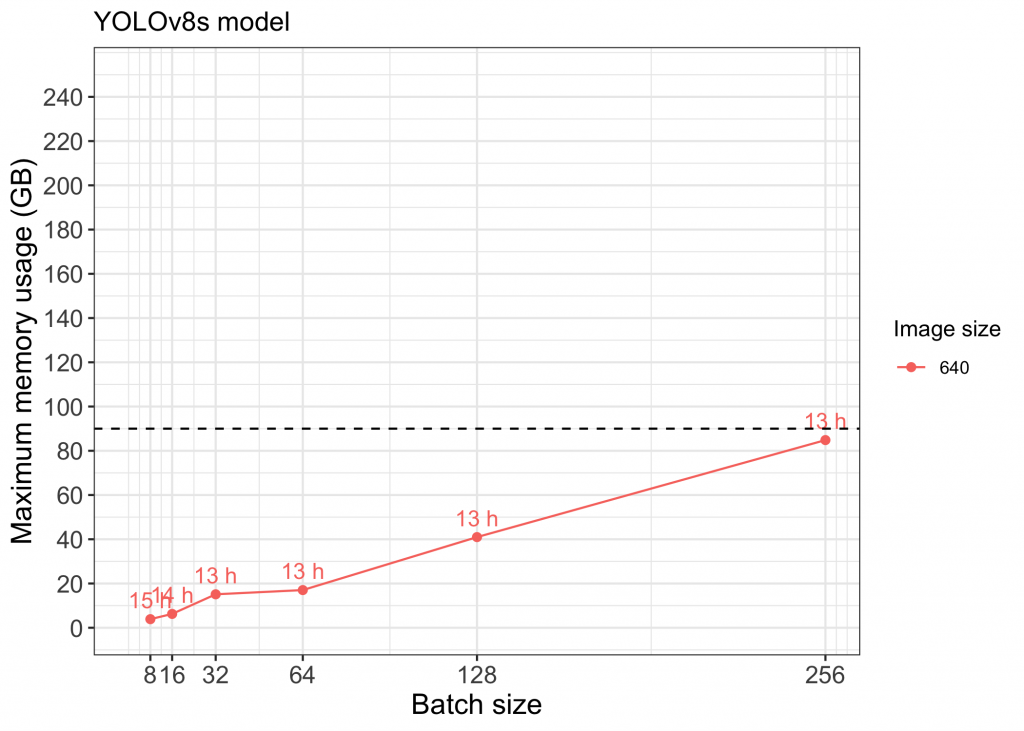
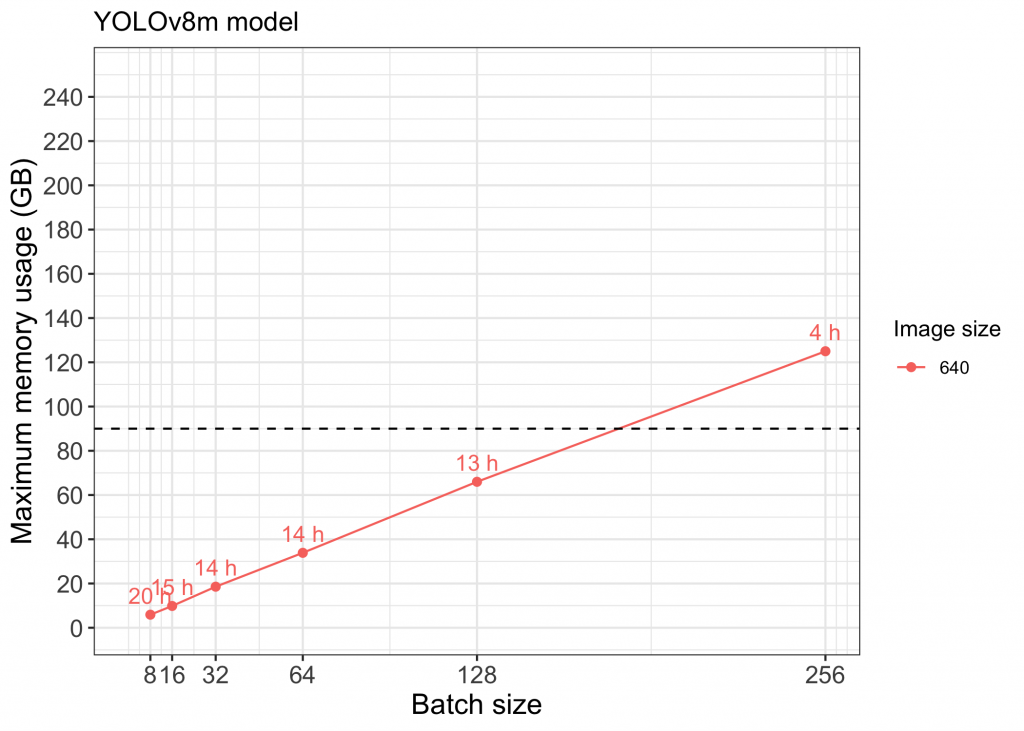
Figure 3 Memory vs Batch size for small models using YOLOv8.
Figure 4 Memory vs Batch size for medium models using YOLOv8. Points above the dashed line (approx. GB limit for each GPU) indicate runs that used NVIDIA NVLink to utilize multiple GPUs
Using individual NVIDIA A100 GPUs, we were able to successfully train YOLOv5s, YOLOv5m, and YOLOv8s models with image size 640 and batch sizes up to 256. Implementing NVIDIA NVLink to enable use of multiple GPUs allowed us to also train models with larger image size and batch size (see points above the dashed line in Figures 1-4). Full capacity of the four A100 GPUs using NVIDIA NVLink was maxed out while training models with image size 1280 above a batch size of 128 (Figure 2).
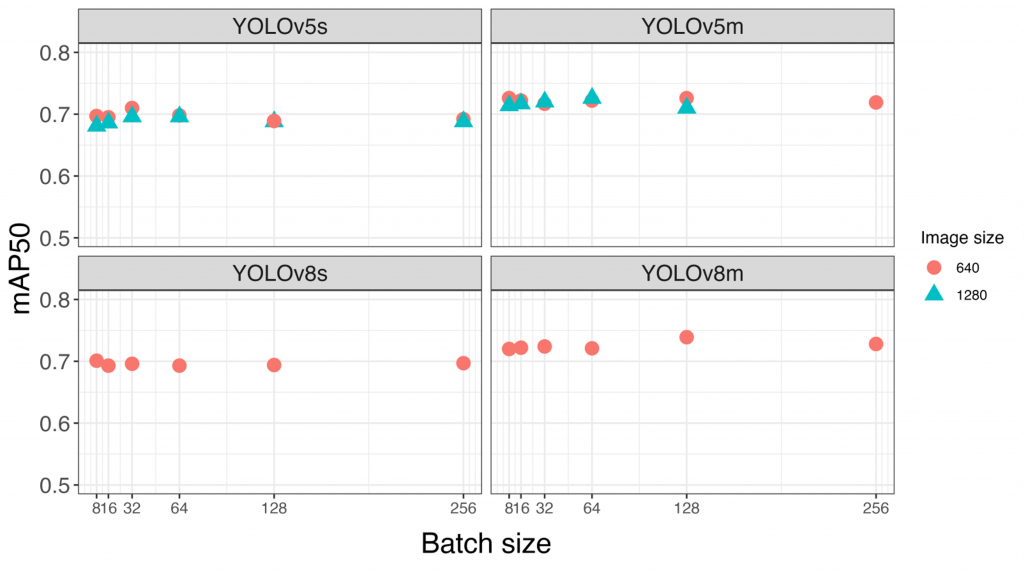
Figure 5 Plotting Mean Average Precision 50% threshold (mAP50) values versus Batch Size for different size models and image sizes. Here as the model size is increased the mAP50 values increases showing we become more accurate and can find more objects over a 50% threshold cutoff value.
Models with more parameters (e.g., YOLOv8m) performed better than smaller models (e.g., YOLOv8s) according to mAP50 values for all classes combined. Additionally, we saw small improvements in models trained using larger batch sizes. Using larger image sizes (1280 compared to 640) did not provide universal improvements, but several individual classes did have higher average precision with models trained on larger image sizes. As expected, these were mostly classes representing smaller-bodied animals. Having the ability to train models using larger image sizes will be important for projects prioritizing the detection of small animals, in particular.

Figure 6 Using YOLOv8 with medium models, the system can identify three deer in the forest.
Conclusions
A well-trained model should be able to detect objects even when obstructed by other items in the image. The image of the baboons in the jungle shows what an accurate, well-trained large model can accomplish. Without this level of accuracy, any data hidden in the images would be lost and not quantified. This workstation was easily able to train new large models leveraging increased batch sizes on thousands of images and at the same time have computer resources to do real-time inference with large model support. Because we are leveraging larger models with support for larger images, we can now start returning the even harder-to-find data like the figure of the Grouse (see below), where the dark blue is the hand labeling from what a person could see, and the light blue is what the new model and larger image size usage can find. This example shows the new trained model is more accurate than the human labeling the data. This type of work becomes important when trying to monitor the forest and areas of our planet with lots of differences or changes in the background. Animals are particularly good at camouflage, and smaller-trained models cannot find well-hidden animals.

Because of this machine, we can now run larger model support at the edge in a ranger station or other structure with limited power and cooling capabilities. We were able to do classification processing every 15 minutes with new data coming in real time without issues using one A100 GPU for images and 32x CPUs and 2x A100 GPUs for processing the sound data (2x sound processes at a time so we could have 15 minutes of collected data done before the next process set started). This machine was able to run in a space with no special cooling and only two NEMA 5-15R plugs for power. The machine did generate some extra heat in the rooms we did our testing from, with onboard fans dissipating the heat captured from the liquid cooling system. The heat and power were very manageable and presented no issues to the spaces we tested. The sound level of the fans did affect the users in that space who did not want to work directly around the machine while it was doing substantial amounts of work like processing and training at the same time. Before this machine, the large models were trained on IBM AC922 servers with NVIDIA V100 Tensor Core GPU that required server rooms with expensive cooling and power distribution. These IBM servers were great but could not be used at the edge and would require data to be sent via a network to leverage them at the edge in any way, since they had limited disk capabilities. With no cell and limited satellite communications, leveraging servers across any network is not feasible when working in forests. The USFS has been looking at NVIDIA Jetson based devices to process data at the edge while training in the cloud on new data, as well as for the dissemination the new models to edge devices. Finally, most of the machines we test have storage space designed for scratch drives and not enough storage for doing a larger experiment. The workstation would be able to scale to around 30TB using 7TB NVMe, enabling larger workloads. This Supermicro Liquid Cooled workstation was the first real device we could run at the edge, do all the workloads required to process data in real time, and continue to retrain models for the future with limited human interaction.

The last thing the USFS group wanted to test was how this system worked at a workstation with video output that could also do the work of a larger server. This Supermicro Liquid Cooled workstation did have an NVIDIA T400 4GB card for the direct video output, and we found that it was a great card for the visual workloads around labeling and viewing new data. Since we built the OSU Njobvu-AI labeling tool to include the ability to train directly from the graphical interface, the OSU Njobvu-AI was built on Node.js and was easy to install and run directly on the desktop. This allowed researchers also working at the edge to graphically interact with the data and continue to hand-label data or train on the NVIDIA A100 GPUs, enabling the ability to verify new models visually. OSU Njobvu-AI can merge projects and provide a review process, and the USFS can have many researchers working independently on these workstations, then send the data back to a central processing group for integration with the larger data sets. Again, because this takes the power and cooling needs of a normal workstation but brings the computer power of a larger AI server, researchers can be using it remotely but aren’t limited to the workloads.
Authors:
Cara L. Appel - Oregon State University College of Agricultural Science, Wildlife Science
Damon B. Lesmeister - United States Forest Service, Pacific Northwest Research Station
Thomas Olson - Oregon State University College of Earth, Oceans and Atmospheric Sciences
Christopher M. Sullivan - Oregon State University College of Earth, Oceans and Atmospheric Sciences